Introduction
Background
Security research rarely targets a single repository. Identifying vulnerability variants, validating detection coverage, and assessing exposure across an organization requires running the same analysis against hundreds or thousands of codebases. Doing this manually (cloning repositories, executing queries, collecting results) does not scale.
Multi-Repository Variant Analysis (MRVA) solves the execution problem. It allows for the execution of CodeQL queries against up to 1,000 repositories in one operation via GitHub Actions. However, it does not solve the reporting problem. Results are returned as individual SARIF artifacts per repository, with no built-in mechanism to consolidate, query, or visualize them across the full analysis.
This project closes that gap. It automates downloading every SARIF file from an analysis run, normalizing results into a single SQLite database, and producing an interactive report. The entire workflow runs inside a GitHub Action. The report is published to GitHub Pages as a static single-page application with no hosted database, no backend server, and no additional security model beyond the repository’s existing access controls.
A live example is available at ghas-projects.github.io/mrva-deploy.
Problem Statement
A MRVA run produces two categories of output:
- Analysis metadata: A summary response from the GitHub Code Scanning API containing per-repository status (scanned, skipped, not found, no CodeQL database, over limit), result counts, and artifact sizes.
- SARIF artifacts: One archive per scanned repository, each containing a SARIF JSON file. The SARIF format is a deeply nested structure of runs, rules, results, code flows, and location metadata. It is designed for machine interchange, not human consumption. Opening a SARIF file does not surface alert counts, severity distributions, affected file paths, or rule coverage at a glance. These must be manually extracted and correlated across the document.
Multiply this across hundreds of repositories and the problem compounds. There is no cross-repository aggregation, no unified query surface, and no way to answer basic questions (“which rule produced the most alerts?”, “which repositories are most affected?”) without writing custom tooling.
Proposed Solution
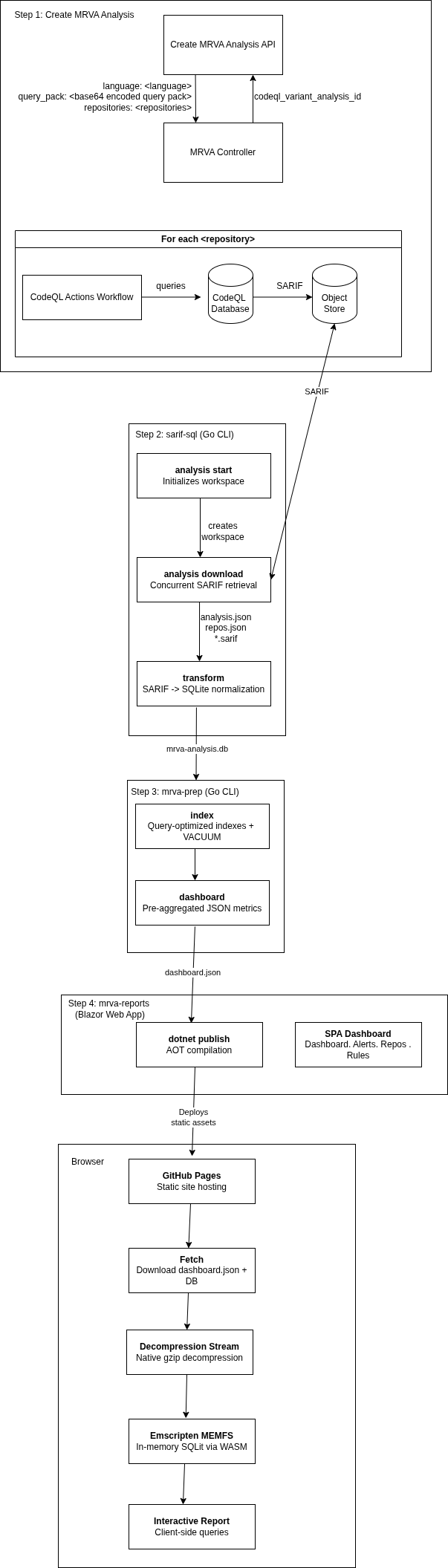
Five components automate the end-to-end MRVA lifecycle:
1. Create MRVA Analysis
Submit a CodeQL variant analysis via the Create a CodeQL variant analysis API. This triggers a GitHub Actions workflow that executes CodeQL queries against up to 1,000 repositories.
2. sarif-sql: SARIF-to-SQL Transform CLI
A Go CLI that downloads and transforms MRVA results:
download: Authenticates via PAT or GitHub App credentials, retrieves analysis metadata, and concurrently downloads SARIF artifact archives for all scanned repositories.transform: Parses SARIF files across a concurrent worker pool, extracts rules, alerts (with source/sink snippets, code flow steps, and fingerprints), and repository metadata, then writes the normalized output to a SQLite database (mrva-analysis.db).
The database contains four tables analysis, repository, rule, alert with foreign key relationships
3. mrva-prep : Data Model Optimization
A CLI application written in go that prepares the database for the reporting UI:
dashboard: Pre-aggregates analysis metrics for fast dashboard rendering.index: Adds query-optimized indexes to the database.compress: Creates a gzip-compressed copy of the SQLite database using maximum compression (gzip level 9) for local testing of the mrva-reports solution.
4. mrva-reports : Interactive Reporting Dashboard
A client-side Blazor WebAssembly application that renders the SQLite database as a static single-page dashboard, deployable to GitHub Pages with no backend:
Dashboard: KPI cards, severity distribution charts, repository coverage breakdowns, and ranked tables for top rules, repositories, and file paths.Alerts: Paginated, searchable data grid with expandable detail views showing code snippets, location metadata, and code flow information.Repositories: Filterable list of scanned repositories with alert counts and analysis status.Rules: Browsable list of triggered CodeQL rules with per-rule alert breakdowns.
At runtime, the gzip-compressed database is streamed to the browser, decompressed via native browser APIs, and loaded into an in-memory SQLite instance through Emscripten. All queries execute client-side.
5. GitHub Actions Orchestration
A GitHub Actions workflow chains steps 2–4 into a single workflow_dispatch trigger: it downloads SARIF artifacts via sarif-sql, prepares the database via mrva-prep, compiles the Blazor WebAssembly application with AOT, and publishes the static output to GitHub Pages. This CI/CD layer is the glue that turns the four standalone components into a fully automated end-to-end pipeline, from MRVA submission to a live, browsable report.
Architecture Diagram
Design Decisions
GitHub Pages over a hosted server
The report is deployed to GitHub Pages rather than a hosted server. This is a deliberate decision to eliminate the security overhead of standing up infrastructure. A self-hosted deployment would require securing the server, managing access control, and deciding on an identity provider — Active Directory, Okta, SAML, or something else — just to control who can view a report. All of which introduce operational burden and risk.
GitHub Pages sidesteps all of this by piggybacking on the repository’s existing permission model. Whoever has access to the deployment repository has access to the report. No additional authentication layer, no network policy, no secrets management for a reporting endpoint. The report is secured by the same GitHub access controls that already govern the repository, so there is nothing new to configure, audit, or maintain.
SQLite in the browser
All query execution happens client-side. The SQLite database is gzip-compressed, streamed to the browser, decompressed via the native DecompressionStream API, and loaded into an in-memory instance through Emscripten. This removes any need for a backend query service, and keeps the deployment model pure static hosting.
Limitations
- 1,000 repository cap - MRVA is limited to 1,000 repositories per analysis run. This is a GitHub API constraint, not a limitation of this project. Larger populations require splitting across multiple runs.
- Browser memory - The entire SQLite database is loaded into browser memory. Practical testing shows databases up to ~500 MB (uncompressed) load reliably on modern desktop browsers. Beyond that, tab crashes become likely depending on the device and available memory. For a typical MRVA run database sizes are well within this range (93MB).
- Static snapshot - The report is a point-in-time snapshot. There is no incremental update or live refresh - re-running the pipeline produces a new report that replaces the previous one.
Documentation Structure
This documentation is organized into two sections:
- User Manual: Installation, configuration, authentication, CLI usage, report generation, and deployment workflows.
- Developer Manual: Architecture, codebase structure, database schema, build system, contribution guidelines, and extension points.